NLP & Topic Modelling
Jun.-Prof. Dr. Mark Hall
Wintersemester 2018/19
NLP Pipeline
Tokenisation
POS-tagging
Dependency tagging
Named Entity Recognition
Tokenisation ist die Umwandlung eines Textstrings in seine einzelnen Bauteile. Dies sind nicht unbedingt
Wörter, da auch z.b. Satzzeichen einzeln ausgezeichnet werden. Daher die Bezeichnung des Ergebnisses als
Tokens.
POS-tagging ist die Annotation der einzelnen Tokens mit ihrer syntaktischen Rolle.
Dependency tagging ist die Annotation der POS-getaggten Tokens mit den syntaktischen Abhängigkeiten zwischen
den Tokens.
Named Entity Recognition ist die Erkennung von Entitäten (Personen, Organisationen, geographische Elemente, ...)
in den POS-getaggten Tokenlisten.
Ansätze in diesem Bereich nutzen heutzutage alle Machine-Learning Techniken.
Tokenisation
Quelltext
'Dies ist ein Beispiel für einen Text.'
wird tokenisiert in
['Dies', 'ist', 'ein', 'Beispiel', 'für', 'einen', 'Text', '.']
Tokenisation
'Hier ist das Büro von Dr. Hall.'
muss tokenisiert werden in
['Hier', 'ist', 'das', 'Büro', 'von', 'Dr.', 'Hall', '.']
und nicht in
['Hier', 'ist', 'das', 'Büro', 'von', 'Dr', '.', 'Hall', '.']
Eine der zentralen Problematiken bei der Tokenisierung ist die Unterscheidung von Punkten die
eine Abkürzung anzeigen ('Dr.') und Punkten die das Satzende markieren ('Hall.').
Tokenisation
'Dies ist die Haus-aufgabe.'
['Dies', 'ist', 'die', 'Haus-aufgabe', '.']
'BAH!—Phyllis: You look very sheepish.—Corydon: I am thinking of ewe.—Ariel.'
Falsch
['BAH!—Phyllis', ':', 'You', 'look', 'very', 'sheepish.—Corydon', ':',
'I', 'am', 'thinking', 'of', 'ewe.—Ariel', '.']
Richtig
['BAH', '!', '—', 'Phyllis', ':', 'You', 'look', 'very', 'sheepish', '.', '—',
'Corydon', ':', 'I', 'am', 'thinking', 'of', 'ewe', '.', '—', 'Ariel', '.']
Satzzeichen können, besonders in historischen Dokumenten eine andere Bedeutung haben, als in modernem
Text (auf den die Tools trainiert wurden). Hier markiert der Gedankenstrich '—' Trennungen zwischen
Teilen des Texts.
POS-Tagging
['Dies', 'ist', 'ein', 'Beispiel', 'für', 'einen', 'Text', '.']
wird getagged als
['PRON', 'VERB', 'DET', 'NOUN', 'ADP', 'DET', 'NOUN', 'PUNCT']
POS - Part Of Speech (Satzteil/Satzrolle)
Ist ein statistischer Ansatz der versucht die für den Wortkontext korrekte Rolle zuzuweisen
POS-Tagging
['Dies', 'ist', 'ein', 'Beispiel', 'für', 'einen', 'Text', '.']
sollte getagged werden als
['PRON', 'VERB', 'DET', 'NOUN', 'ADP', 'DET', 'NOUN', 'PUNCT']
wird getagged als
['PRON', 'AUX', 'DET', 'NOUN', 'ADP', 'DET', 'NOUN', 'PUNCT']
"ist" ist an der Stelle generell ein Auxilliarverb, aber in diesem Kontext ist es das Hauptverb
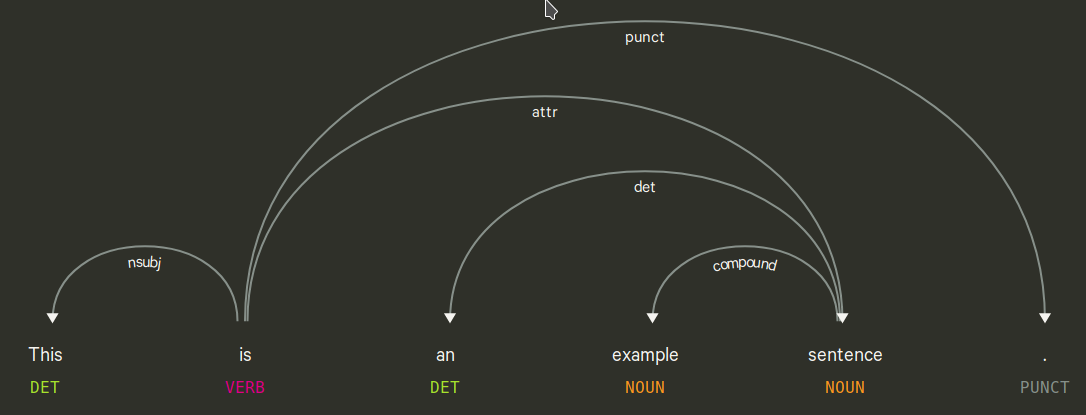
Dependency Tagging
Named Entity Recognition
['Das', 'Beatles', 'Museum', 'ist', 'in', 'Halle', '.']
[('Beatles Museum', 'ORG'), ('Halle', 'LOC')]
Das Ziel der Named Entity Recognition is ein oder mehr-wortige Nomen zu identifizieren die auf konkrete
Entitäten verweisen. Zusätzlich soll auch die Kategorie der Entität extrahiert werden.
Die Standardkategorien sind: Organisationen, Personen, Orte, Datum, Zahlen (mit Einheiten), Events
Word2Vec
Wort + Kontext → Vektorraum
['Das', 'Beatles', 'Museum', 'ist', 'in', 'Halle']
[['Das', 'Beatles', 'Museum'], ['Beatles', 'Museum', 'ist'],
['Museum', 'ist', 'in'], ['ist', 'in', 'Halle']]
"You shall know a word by the company it keeps"
n-Gramme werden über ein Sliding-Window das über den Text fährt generiert
Aufgrund der n-Gramme wird dann eine zuweisung in einen Vektorraum mittels eines flachen neuronalen Netzes
gelernt (Dimensionalität generell zwischen 100 und 1000)
Jedes Wort erhält einen Vektor, wobei Wörter die in ähnlichen Kontexten verwendet werden, auch ähnliche
Vektoren erhält.
Das Model kann dann also als Ähnlichkeitsquelle genutzt werden, z.b. für Vorschläge, Suche über ähnliche
Wörter, ...
Die Qualität des Vektorraums hängt stark von den gewählten Hyperparametern ab (Dimensionalität, Sliding
Window Größe [5 generell empfohlen], Lernalgorithmus)
Topic Modelling
Die Dokumente in einer Sammlung gehören generell zu einem oder mehreren Themen. Diese Themen werden aber
generell nicht explizit in den Dokumenten als Meta-daten deklariert. Sie sind "latente" Themen.
Ziel des Topic Modelling ist es diese impliziten Themen mittels statistischer Methoden explizit zu machen.
Anders als Word2Vec nutzen diese generell keine neuronalen Netze, sondern sind statistische Methoden
Topic Modelling sieht auch das Dokument als das primäre Objekt und nicht das Wort
Topic Modelling passiert meistens auf der sogenannten bag-of-words struktur: [(token1, häufigkeit), (token2, häufigkeit), ...]
Dictionary generierung
['Das', 'Beatles', 'Museum', 'ist', 'in', 'Halle']
['Beatles', 'Museum', 'Halle']
{'Beatles': 0, 'Museum': 1, 'Halle': 2}
Tokenisation liefert eine Liste an Tokens die genau den Text wiedergeben. Wörter die aber sehr oft oder
sehr selten vorkommen sind aber für Berechnung von Topic Models generell schlecht.
Häufige Wörter verlangsamen den Vorgang, erlauben aber kaum Unterscheidungen zwischen den Themen
Wörter die sehr selten vorkommen sind schwer einzuordnen, da sie nur sehr wenig Kontext anbieten
Mit Wörtern zu arbeiten ist langsam, das Wörterbuch enthält daher ein Mapping von Wörtern zu IDs (und umgekehrt)
Latent Semantic Indexing
Anwendung von Single-Value-Decomposition (SVD charakterisiert ähnlich wie Eigenvektoren eine Matrix) auf
bag-of-words.
Bettet die Worte dann in einen niedriger dimensionalen Raum ein
Semantische Indizierung weil ähnliche Wörter ähnlicher in dem Raum lokalisiert werden
Ein Wort kann nur eine Bedeutung haben (einen Punkt im Raum)
Latent Dirichlet Allocation
Definiert Dokumente als probabilistische Generierungen von Topics, wobei jedes Topic wiederum eine
probabilistische Generierung von Wörtern ist
Das probabilistische Mapping Wörter - Topics - Dokumente wird aus Sampledaten gelernt
Code Beispiele
import spacy
nlp = spacy.load('en_core_web_lg')
tokens = nlp("The sun's light is a shadow compared to your beauty")
tokens[0].text == 'The'
tokens[0].lemma_ == 'the'
tokens[0].pos_ == 'DET'
tokens[0].is_stop == False
Code Beispiele
import spacy
from gensim.corpora import Dictionary
nlp = spacy.load('en_core_web_lg')
dictionary = Dictionary()
with open('ap.txt') as input_file:
for line in input_file.readlines():
tokens = nlp(line)
dictionary.add_documents([[t.lemma_ for t in tokens if not t.is_stop]])
dictionary.filter_extremes()
dictionary.compactify()
Über die Eingabedaten iterieren
Für jede Zeile alle tokens die nicht Stoppwörter sind dem Dictionary hinzufügen
Wir nutzen die Lemmata als Tokens, man könnte aber auch den reinen Text nutzen
Danach extreme Tokens filtern (Tokens die sehr selten vorkommen, Tokens die in den meißten Documenten vorkommen)
Tokens neu durchnummerieren, da durch das Filtern löcher in der Tokenidliste entstehen
Code Beispiele
corpus = []
with open('ap.txt') as input_file:
for line in input_file.readlines():
tokens = nlp(line)
corpus.append(dictionary.doc2bow([t.lemma_ for t in tokens if not t.is_stop]))
Der Korpus ist einfach eine Liste von Listen
Jedes Dokument wird von einer Tokenliste in eine bag-of-words liste umgewandelt und dem Korups hinzugefügt